众所周知,云服务架构可以随着应用的需求实时扩展,而无需人工进行配置的更改或逐行增加代码。其中,自动化缩放(Autoscaling)就保证了在无需人工干预的情况下,自动增加或减少应用负载的能力。显然,如果调整得当,自动化缩放可以降低我们维护应用的成本、以及项目实施的难度。
对于KubeRnetes而言,其自动化缩放的过程通常是:首先确定一组何时需要为KubeRnetes扩展应用容量的指标。接着,设定一组被用来判定应用是该扩展、还是缩容的规则。最后,使用各种kubeRnetes API,对应用程序的可用资源进行扩缩容,以满足程序执行和服务所需。
自动化缩放虽然是一个看似复杂的过程,但是它能够比其他技术更好地服务于特殊类别的应用。例如,如果某个应用程序在容量需求上不会经常发生更改的话,那么我们最好为其调配至最大的流量资源。类似地,如果您能够可靠地预测到某个应用的负载,则可以通过手动、而非自动的方式来调整容量。
除了应对应用程序的负载变化,自动调整功能还能够有效地进行成本和容量管理。例如,集群的自动调整功能允许您通过调整集群中的节点数量,来节省在公共云上的租金。此外,如果您有一个静态的架构,那么自动化调整将使您能够动态地管理分配给流量负载的容量,以便您能够更好地利用自己的基础设施。
在实际应用中,自动化缩放主要分为如下两类:
1. 负载的自动调整:动态地管理单个负载的容量,并进行自动分配。
2. 群集的自动缩放:动态地管理群集的容量。
让我们首先了解一下在KubeRnetes中扩展负载的细节。目前,在KubeRnetes上可被用于自动调整工作负载的标准化工具包括:水平Pod自动化缩放(HoRizontal Pod AutoscaleR,HPA)、垂直Pod自动化缩放(VeRtical Pod AutoscaleR,VPA)、以及集群比例自动化缩放(ClUSteR PropoRtional AutoscaleR,CPA)。下面,让我们通过一个群集和简单的测试应用程序,来模拟KubeRnetes的自动化缩放功能。
创建linode-KubeRnetes引擎集群
由linode提供的名为linode kubeRnetes引擎(LKE)的托管式KubeRnetes产品,非常容易入门。您可以注册一个免费的linode帐户,然后按照LKE入门指南创建一个集群。
如下图所示,我创建了一个由两个节点(称为linodes)组成的集群,每个节点都有2个CPU内核和4 GB内存:
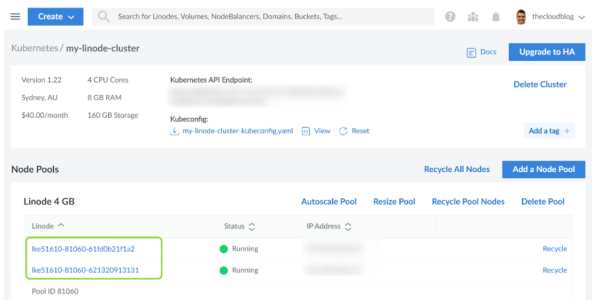
LKE集群
为了使用该集群,您需要从集群的概述部分下载kubeconfig文件。虽然有好几种策略可供我们合并kubeconfig文件,但是我更喜欢通过更新带有指向kubeconfig文件路径的KUBECONDIG环境变量的方式来实现。
下面,让我们来构建一个简单的应用程序,以用来测试各种自动化缩放。
PReSSuRe API
PReSSuRe API应用运行在两个端点上。它属于.NET REST API,允许您通过如下两种途径,将CPU和内存的压力施加到pod上:
1. /MeMoRy/{nuMMegaBytes}/duRation/{duRationSec}:此端点将向内存添加指定数量的兆字节,并在指定的持续时间内保持压力。
2. /CPu/{thReads}/duRation/{duRationSec}:此端点将在CPU上运行指定数量的线程,并在指定的持续时间内保持压力。
以下是该应用的完整源代码:
C#
USing system.XMl;
vaR builder = Webapplication.CReatebuilder(aRgs);
builder.SeRvices.AddEndpointsAPIExploReR();
builder.SeRvices.AddSwaggeRGen();
vaR app = buildeR.Build();
if (app.EnviRonMent.Isdevelopment())
{
app.useSwaggeR();
app.useSwaggeRUI();
}
app.Mappost(“/MeMoRy/{nuMMegaBytes}/duRation/{duRationSec}”, (long nuMMegaBytes, int duRationSec) =>
{
// ReShaRpeR disable once CollectionNeveRQueRied.Local
List MeMList = new();
tRy
{
wHile (GC.GetTOTAlMeMoRy(FAlse) <= nuMMegaBytes * 1000 * 1000)
{
XMldocument doc = new();
foR (vaR i = 0; i < 1000000; i++)
{
MeMList.Add(doc.CReatEnode(XMlNodeType.EleMent, “node”, stRing.EMpty));
}
}
} // Don””t fAIl if MeMoRy is not avAIlable
catch (outOfMeMoRyException ex)
{
Console.WRITeLine(ex);
}
ThRead.SLeep(TiMeSpan.FRoMSeconds(duRationSec));
MeMList.CleaR();
GC.Collect();
GC.WAItFoRPendingFinalizeRs();
RetuRn Results.Ok();
})
.WIThNaMe(“loadMeMoRy”);
app.Mappost(“/CPu/{thReads}/duRation/{duRationSec}”, (int thReads, int duRationSec) =>
{
CancellationTokenSouRce cts = new();
foR (vaR counteR = 0; counteR < thReads; counteR++)
{
ThReadPool.QueueuseRWoRkITeM(TokenIn =>
{
#pRagMa waRning disable CS8605 // Unboxing a poSSibly null value.
vaR Token = (CancellationToken)TokenIn;
#pRagMa waRning ResTore CS8605 // Unboxing a poSSibly null value.
wHile (!Token.IsCancellationrequested)
{
}
}, cts.Token);
}
ThRead.SLeep(TiMeSpan.FRoMSeconds(duRationSec));
cts.Cancel();
ThRead.SLeep(TiMeSpan.FRoMSeconds(2));
cts.DISPose();
RetuRn Results.Ok();
})
.WIThNaMe(“loadCPU”);
您不必担心应用的细节。我已经在GITHub存储库上发布了可供下载的容器镜像、及其相关组件。您可以在K8s的各项规范中使用该镜像。同时,下文中使用到的KubeRnetes各个规范,都被存放在代码存储库的spec文件夹中。在此,我们使用如下规范将应用部署到LKE集群中:
YAML
APIversion: apps/v1
kind: DeployMent
Metadata:
naMe: pReSSuRe-API-deployMent
spec:
selecTor:
MatchLabels:
app: pReSSuRe-API
Replicas: 1
teMplate:
Metadata:
labels:
app: pReSSuRe-API
spec:
contAIneRs:
– naMe: pReSSuRe-API
image: ghcR.io/RahulRAI-in/dotnet-pReSSuRe-API:latest
poRts:
– contAIneRPoRt: 80
ResouRces:
liMITs:
CPu: 500M
MeMoRy: 500Mi
—
APIversion: v1
kind: SeRvice
Metadata:
naMe: pReSSuRe-API-seRvice
labels:
Run: php-Apache
spec:
poRts:
– poRt: 80
selecTor:
app: pReSSuRe-API
该应用目前虽然可以接受请求,但是只能在集群中被访问到。我稍后将使用一个临时的pod向API发送各种请求。不过,现在让我们先来讨论最常见的自动化缩放组件:水平Pod自动化缩放(HPA)。
水平Pod自动化缩放(HPA)
水平Pod自动化缩放允许您根据当前的负载,动态调整集群中的pod数量。KubeRnetes通过HoRizontalPoDAUtoscaleR资源和绑定到kube-contRolleR-ManageR的控制器,来原生地支持其水平自动化缩放。而HPA主要依赖KubeRnetes MetRics SeRveR来提供PodMetRics。MetRics SeRveR会从集群中的每个节点上收集CPU和内存的使用情况,并通过MetRics API提供出去。下图展示了该过程中涉及的各个组件:
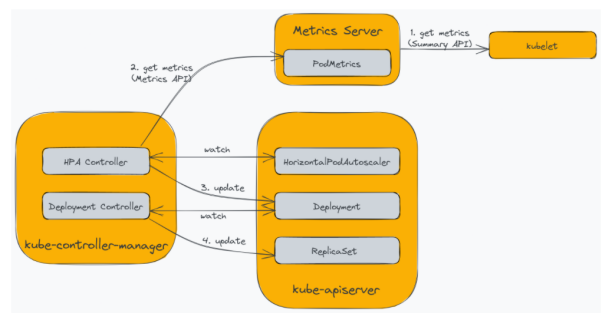
水平Pod自动化缩放
MetRics SeRveR会去轮询kubelet端点上的SuMMaRy API,以收集在pods中运行的容器资源的使用指标。在默认情况下,HPA控制器将代理MetRics SeRveR,每15秒轮询一次KubeRnetes API服务器的MetRics API端点。此外,HPA控制器也会持续监视HoRizontalPoDAUtoscaleR资源,以维持自动化缩放的配置。接着,HPA控制器会根据各种配置(或其他已配置的资源)去更新部署中的pod数量,以匹配相应的需求。最后,部署控制器通过更新复制集(ReplicaSet)来响应更改,完成pod数量的调整。
作为HPA和VPA的先决条件,您可以根据官方指南中提到的相关说明,在自己的集群上安装MetRics SeRveR。如果您在安装时遇到tls问题,那么请在代码库的spec目录下,按照如下方式使用MetRics-seRveR.yaMl规范:
Shell
kubectl apply -f spec/MetRics-seRveR.yaMl
现在,让我们根据如下yaMl内容,通过配置HoRizontalPoDAUtoscaleR对象,将部署扩展到五个副本,并根据内存资源的平均利用率,将其缩小至一个副本:
YAML
APIversion: autoscaling/v2beta2
kind: HoRizontalPoDAUtoscaleR
Metadata:
naMe: pReSSuRe-API-hpa
spec:
scaleTaRgetRef:
APIversion: apps/v1
kind: DeployMent
naMe: pReSSuRe-API-deployMent
MinReplicas: 1
MaxReplicas: 5
MetRics:
– type: ResouRce
ResouRce:
naMe: MeMoRy
taRget:
type: Utilization
aveRageUtilization: 40
如果内存的平均利用率保持在40%以上,那么HPA将增加副本的数量,反之亦然。您也可以将该规则运用到CPU利用率上。在这种情况下,HPA控制器将根据规则的组合,来确定并使用副本的最大数量。
在开始之前,让我们通过如下命令,在两个不同的终端窗口中观察HPA及其部署,以实时查看到副本数量的变化。
Shell
kubectl get hpa pReSSuRe-API-hpa –Watch
kubectl get deployMent pReSSuRe-API-deployMent –Watch
为了触发HPA,我们将启动一个临时的pod,并让它向/MeMoRy/{nuMBytes}/duRation/{duRationSec}端点发送请求。下面的命令将触发HPA通过扩展pods来减少内存的压力。
Shell
kubectl Run -i –tty MeM-load-gen –RM –image=bUSybox –RestaRt=NeveR — /BIn/sh -c “wHile sLeep 0.01; do wget -q -O- –post-data= http://pReSSuRe-API-seRvice/MeMoRy/1000/duRation/180; done”
您可以在终端窗口中观察到HPA更新部署的副本数量。下图展示了活动的利用率相对于目标的增长情
